
 Eva Strauss
Eva StraussAfter years of planning, development, and overcoming setbacks, Comporium’s new Customer Self Service MyComporium application went live in August 2023...
 Eva Strauss
Eva StraussAfter years of planning, development, and overcoming setbacks, Comporium’s new Customer Self Service MyComporium application went live in August 2023...
 Jack Miszencin
Jack MiszencinQuoin customized the Primero platform to cater to the particular needs of Barry Callebaut, a Belgian-Swiss chocolate company, which has committed to eliminating child labor from its supply chain entirely by 2025...
 Traci Moore
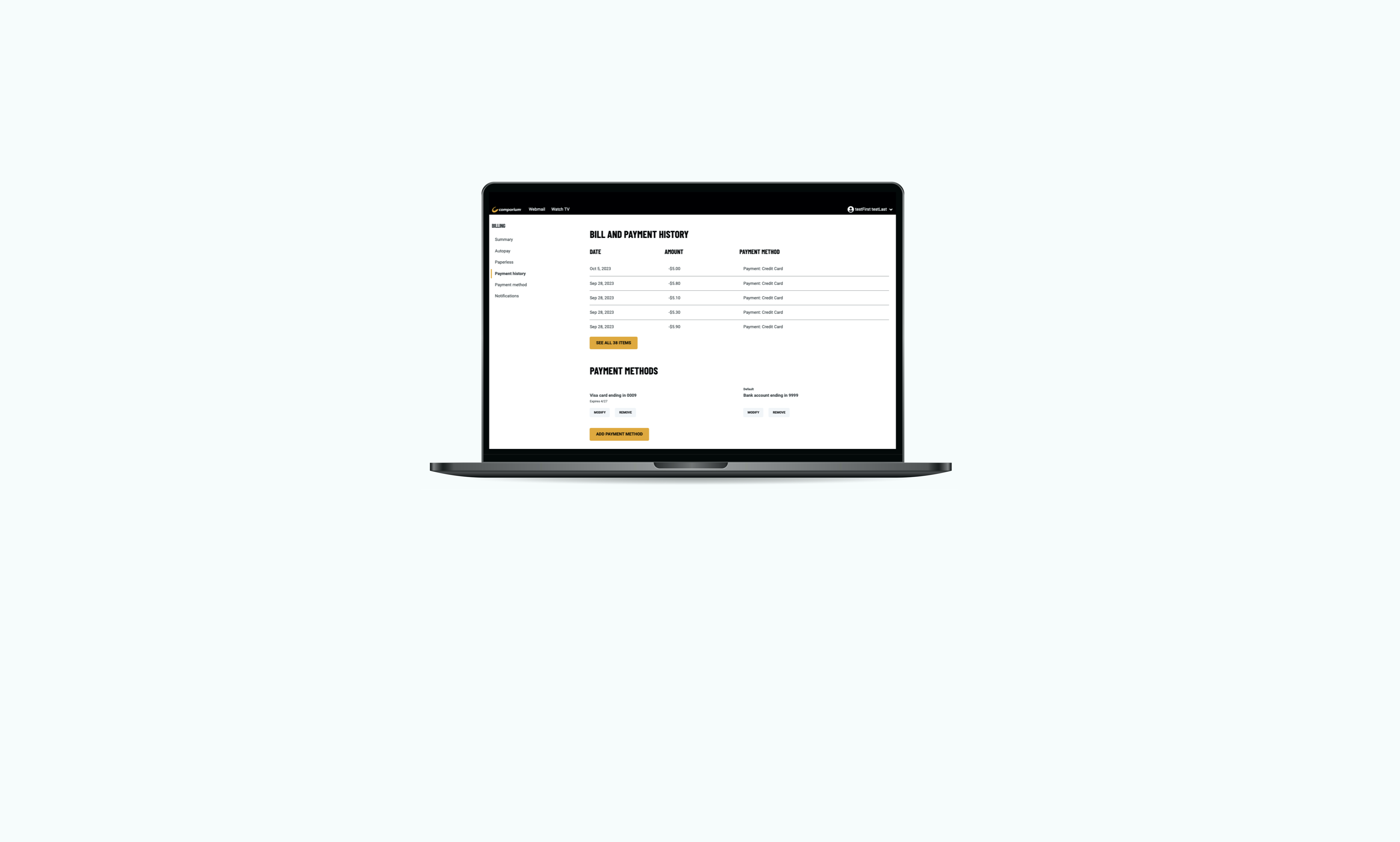
Traci MooreOut with the old and in with the new, how modernizing a web application can improve a user's experience
 Eva Strauss
Eva StraussA client was struggling to improve an online presence that was practically zero, but Quoin's focus on the basics revolutionized their SEO ranking and site traffic.
 Brad Kain
Brad KainWho actually bears more risk in a conventional fixed cost agreement - the outsource development team or the client?
Our dedicated staff of creative minds allows us to provide a large list of capabilities and solutions to fit any business needs.
- Digital Transformation
- Analytics & Data Management
- Mobile-to-Enterprise
- Digital Experience